Introducción a Apache kafka parte 1
3 septiembre, 2022
7 minutos de lectura
¿Ves algún error o quieres modificar algo? Haz una Pull Request
Introducción a apache kafka
Hace alrededor de 4 años que trabajo con una de las tecnologías que mas me motiva en el mundo del desarrollo de aplicaciones distribuidas y la ingeniería de datos. Su nombre es apache kafka , No voy a mentir la primera vez que escuche su nombre me vino a la mente el siguiente libro La metamorfosis escrita por Franz Kafka.
Pero si nos dirigimos al sitio oficial de este proyecto de código abierto, esta sería la descripción general que nos ofrece.
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Pero para que se usa un event streaming platform ?.
- Para procesar(
process) pagos y transacciones financieras en tiempo real. - Para rastrear(
track) y monitorear(monitor) automóviles, camiones, flotas y envíos en tiempo real, que tengan impacto en procesos de logística y la industria automotriz. - Para capturar(
capture) y analizar(analyze) continuamente datos de sensores de dispositivos IoT u otros equipos, como en fábricas. - Para recopilar(
collect) y reaccionar(react) de inmediato a las interacciones y pedidos de los clientes, como en el comercio minorista, la industria hotelera y de viajes, y las aplicaciones móviles. - Monitorear(
monitor) a los pacientes en atención hospitalaria y predecir cambios de condición para asegurar un tratamiento oportuno en emergencias. - Servir como base para plataformas de datos, arquitecturas basadas en eventos y microservicios.
Todos estos casos de usos pueden variar teniendo siempre en cuenta la necesidad real en la que se mueve nuestro entorno.
Características que identifican a apache Kafka
Kafka combina tres características esenciales:
publish/subscribepublicar (escribir) y suscribirse a (leer) flujos de eventos.storealmacena secuencias de eventos de forma duradera y fiable durante el tiempo que se defina.processprocesar flujos de eventos a medida que ocurren o retrospectivamente.
Es válido recalcar que estas funcionalidades se comportan de manera distribuida, altamente escalable, elástica, segura y tolerante a fallas. Brindando una plataforma confiable y segura para poder llevar a cabo desarrollos de productos digitales que aprovechen al máximo estas características.
¿Cómo funciona Kafka en pocas palabras?
Kafka es un sistema distribuido que consta de servidores y clientes que se comunican a través del protocolo TCP.
Se puede desplegar en hardware básico, máquinas virtuales y contenedores en entornos locales y en la nube.
Server: Kafka se ejecuta como un clúster de uno o más servidores.
Algunos de estos servidores forman la capa de almacenamiento, llamados intermediarios.
Otros servidores ejecutan Kafka Connect para importar y exportar datos como flujos de eventos.
con la misión de integrar Kafka con sistemas existentes, como bases de datos y otros clústeres de Kafka.
Un clúster de Kafka es altamente escalable y tolerante a fallas:
Si alguno de sus servidores falla, los otros servidores se harán cargo de su trabajo para garantizar operaciones continuas sin pérdida de datos.
Clients: Le permiten escribir aplicaciones distribuidas y microservicios que leen, escriben y procesan flujos de eventos
en paralelo, con tolerancia a fallas, incluso en el caso de problemas de red o fallas de máquinas.
Conceptos principales y terminología
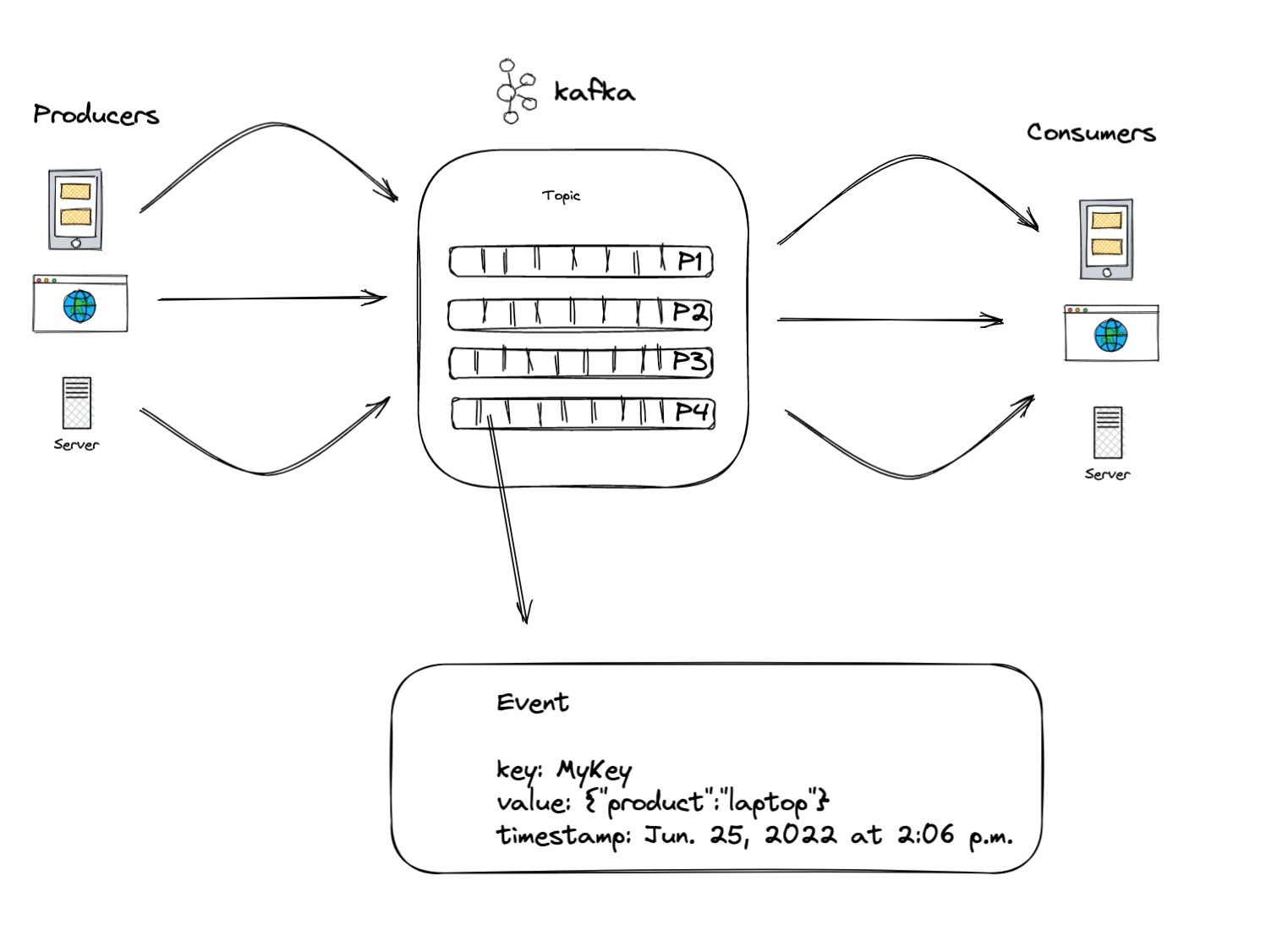
Un evento(event) registra el hecho de que "algo sucedió".
Cuando se lee o escribe datos en Kafka, se realiza en forma de eventos.
Conceptualmente, un evento tiene una clave, un valor,
una marca de tiempo además de tener encabezados de metadatos opcionales.
Aquí hay un evento de ejemplo
- Event key: "Alice"
- Event value: "Made a payment of $200 to Bob"
- Event timestamp: "Jun. 25, 2022 at 2:06 p.m."
Los productores(producers) son aquellas aplicaciones cliente que publican (escriben)
eventos en Kafka,
y los consumidores (consumers) son los que se suscriben (leen y procesan) estos eventos.
En Kafka, los producers y los consumers están totalmente desvinculados
y son independientes entre sí, lo cual es un elemento de diseño clave para lograr
la alta escalabilidad por la que se conoce a Kafka.
Los eventos se organizan y almacenan de forma duradera en temas (topics).
Muy simplificado,un tema es similar a una carpeta en un sistema de archivos,
y los eventos son los archivos en esa carpeta.
Un ejemplo de nombre de tema podría ser "pagos".
Los topics en Kafka son siempre multi productor y multi suscriptor:
un tema puede tener cero, uno o muchos producers que escriben eventos en él,
así como cero, uno o muchos consumers que se suscriben a estos eventos.
Los eventos de un tema se pueden leer tantas veces como sea necesario;
a diferencia de los sistopics de mensajería tradicionales,
los eventos no se eliminan después del consumo.
En su lugar, usted define durante cuánto tiempo Kafka debe retener
sus eventos a través de una configuración por tema,
después de lo cual se descartan los eventos antiguos.
El rendimiento de Kafka es efectivamente constante con respecto al tamaño de los datos,
por lo que almacenar datos durante mucho tiempo está perfectamente bien.
Los topics están particionados (partitions), lo que significa que un tema se distribuye en varios "cubos"
ubicados en diferentes brokers de Kafka. Esta ubicación distribuida de sus datos
es muy importante para la escalabilidad porque permite que las aplicaciones de
los clientes lean y escriban los datos desde/hacia muchos brokers al mismo tiempo.
Cuando se publica un nuevo evento en un tema, en realidad se agrega a una de
las particiones del tema. Los eventos con la misma clave de evento
(por ejemplo, un ID de cliente o de vehículo) se escriben en la misma partición,
y Kafka garantiza que cualquier consumidor de una partición de tema dada siempre
Leerá los eventos de esa partición exactamente en el mismo orden en que fueron escritos.
Para que sus datos sean tolerantes a fallas y estén altamente disponibles,
cada tema se puede replicar, incluso entre regiones geográficas o centros de datos,
de modo que siempre haya varios intermediarios que tengan una copia de
los datos en caso de que algo salga mal, usted desea hacer el mantenimiento de
los brokers, y así sucesivamente. Una configuración de producción común es un
factor de replicación de 3, es decir, siempre habrá tres copias de sus datos.
Esta replicación se realiza a nivel de particiones de tema.
Primeros pasos con apache kafka
Seguramente si estás en esta parte del artículo querrás ver de forma práctica cómo funciona esta plataforma al menos en sus aspectos básicos como los descritos en el diagrama anterior. Para ello realizaremos el proceso de descarga de la herramienta en su sitio oficial.
wget https://downloads.apache.org/kafka/3.2.1/kafka_2.13-3.2.1.tgz
tar -xcvf kafka_2.13-3.2.1.tgz
A la versión de este tutorial nos encontramos con la versión kafka_2.13-3.2.1.tgz
Como correr nuestro propio cluster de apache kafka local
Para realizar esta tarea una vez descargado y descomprimido el fichero kafka_*.tgz procedemos
ha seguir los siguientes pasos.
Paso 1, ejecutar nuestra instancia de apache zookeeper.
Nota: apache zookeeper es la plataforma que se encarga de orquestar y controlar nuestros nodos de apache kafka.
cd kafka_<version>
./bin/zookeeper-server-start.sh ./config/zookeeper.properties
...
[2022-09-04 12:55:03,754] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
[2022-09-04 12:55:03,761] INFO Using org.apache.zookeeper.server.watch.WatchManager as watch manager (org.apache.zookeeper.server.watch.WatchManagerFactory)
...
Luego de haber ejecutado nuestro apache zookeeper procedemos a ejecutar nuestro apache kafka
./bin/kafka-server-start.sh ./config/server.properties
...
[2022-09-04 12:58:50,519] INFO Kafka version: 3.2.1 (org.apache.kafka.common.utils.AppInfoParser)
[2022-09-04 12:58:50,519] INFO Kafka commitId: b172a0a94f4ebb9f (org.apache.kafka.common.utils.AppInfoParser)
[2022-09-04 12:58:50,520] INFO Kafka startTimeMs: 1662310730518 (org.apache.kafka.common.utils.AppInfoParser)
[2022-09-04 12:58:50,521] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)
...
Ya con estos dos pasos tenemos nuestro servidor de apache kafka corriendo por el port:9092 en nuestra máquina localhost
Ya para poder acceder a nuestro servidor podremos usar clientes externos o el propio que provee nuestro servidor de apache kafka el cual también se encuentra dentro de la carpeta bin.
ls ./bin/
connect-distributed.sh kafka-consumer-perf-test.sh kafka-producer-perf-test.sh kafka-verifiable-consumer.sh
connect-mirror-maker.sh kafka-delegation-tokens.sh kafka-reassign-partitions.sh kafka-verifiable-producer.sh
connect-standalone.sh kafka-delete-records.sh kafka-replica-verification.sh trogdor.sh
kafka-acls.sh kafka-dump-log.sh kafka-run-class.sh windows
kafka-broker-api-versions.sh kafka-features.sh kafka-server-start.sh zookeeper-security-migration.sh
kafka-cluster.sh kafka-get-offsets.sh kafka-server-stop.sh zookeeper-server-start.sh
kafka-configs.sh kafka-leader-election.sh kafka-storage.sh zookeeper-server-stop.sh
kafka-console-consumer.sh kafka-log-dirs.sh kafka-streams-application-reset.sh zookeeper-shell.sh
kafka-console-producer.sh kafka-metadata-shell.sh kafka-topics.sh
kafka-consumer-groups.sh kafka-mirror-maker.sh kafka-transactions.sh
Otras alternativas pueden ser las siguientes herramientas:
Llegado a este punto ya nos encontramos en condiciones para usar nuestro server de apache kafka en futuros proyectos. Por lo que en próximos artículos estaremos abordando temas como seguridad, clusters y desarrollo de aplicaciones. Espero que te sea de utilidad este contenido y nos vemos en el próximo capítulo.
Recursos
- Apache Kafka sitio oficial
- Cómo instalar Apache Kafka en Ubuntu 18.04